Trong lĩnh vực Khoa học máy tính, cấu trúc dữ liệu được định nghĩa là những phương pháp để tổ chức và lưu trữ dữ liệu trong máy tính nhằm tăng hiệu suất của việc thực hiện các hoạt động trên dữ liệu. Cấu trúc dữ liệu rất quan trọng trong nhiều lĩnh vực của Khoa học máy tính và Kỹ thuật Phần mềm.
Các cấu trúc dữ liệu được sử dụng trong hầu hết các chương trình và phần mềm đã được phát triển. Chúng tuân theo các nguyên tắc cơ bản của Khoa học máy tính và Kỹ thuật Phần mềm. Ngoài ra, kiến thức về cấu trúc dữ liệu là một yếu tố quan trọng trong các cuộc phỏng vấn ngành Kỹ thuật phần mềm. Vì vậy, như một lập trình viên, chúng ta cần phải nắm vững kiến thức về các cấu trúc dữ liệu. Trong bài viết này, mình sẽ giải thích về 8 cấu trúc dữ liệu quan trọng mà mọi lập trình viên cần biết.
Mảng (Array)
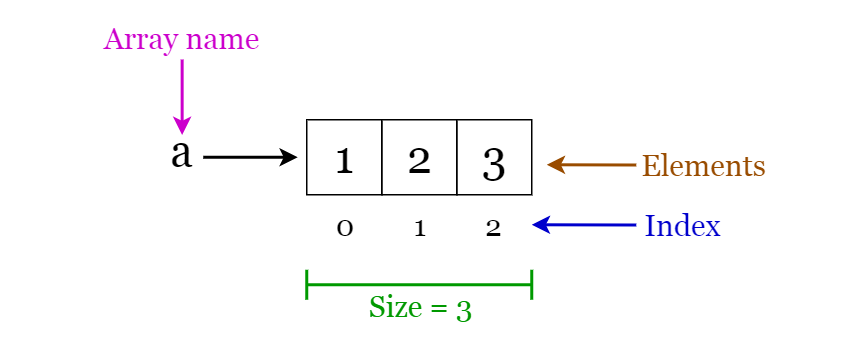
Mảng là một cấu trúc dữ liệu có kích thước cố định, được sử dụng để lưu trữ các phần tử cùng kiểu dữ liệu. Có thể là một mảng các số nguyên, mảng các số thực, mảng ký tự, hoặc thậm chí một mảng của các mảng (mảng 2 chiều). Mảng được đánh chỉ mục, cho phép ta truy cập ngẫu nhiên vào các phần tử.
Các phép toán trên mảng
- Truy cập ngẫu nhiên: Cho phép ta truy cập vào một phần tử bất kỳ trong mảng bằng cách sử dụng chỉ mục (index) của nó.
- Tìm kiếm: Tìm kiếm một phần tử trong mảng bằng cách sử dụng chỉ mục hoặc giá trị của nó.
- Cập nhật: Cập nhật giá trị của một phần tử đã tồn tại trong mảng thông qua chỉ mục của nó. Để thêm hoặc xoá phần tử trong mảng, chúng ta cần tạo một mảng mới với kích thước tăng hoặc giảm, sau đó sao chép các phần tử từ mảng cũ và thêm phần tử mới vào.
Ứng dụng của mảng
- Sử dụng để xây dựng các cấu trúc dữ liệu khác như danh sách mảng (array list), cây (heap), bảng băm (hash table), vector hay ma trận.
- Sử dụng cho các thuật toán sắp xếp như sắp xếp chèn (insertion sort), sắp xếp nhanh (quick sort), sắp xếp nổi bọt (buble sort), sắp xếp trộn (merge sort).
Danh sách liên kết (Linked list)
Danh sách liên kết là một cấu trúc dữ liệu tuần tự bao gồm một chuỗi các phần tử theo thứ tự tuyến tính và được liên kết với nhau. Ta chỉ có thể truy cập tuần tự vào danh sách liên kết, không thể truy cập ngẫu nhiên. Danh sách liên kết cung cấp một cấu trúc dữ liệu đơn giản và linh hoạt cho việc thao tác với dữ liệu động.
Quy tắc của một danh sách liên kết
- Node: Các phần tử trong danh sách liên kết được gọi là các node.
- Key: Mỗi node chứa một giá trị và một con trỏ trỏ tới node kế tiếp, được gọi là “next”.
- Head: Thuộc tính “head” trỏ tới node đầu tiên của danh sách liên kết.
- Tail: Phần tử cuối cùng của danh sách liên kết được gọi là “tail”. Có một số loại danh sách liên kết, bao gồm:
- Danh sách liên kết đơn: Duyệt các phần tử theo chiều tiến.
- Danh sách liên kết đôi: Duyệt các phần tử theo cả chiều tiến và chiều lùi. Các node có một con trỏ “pre” trỏ tới node trước đó.
- Danh sách liên kết vòng: Là một danh sách liên kết đôi đặc biệt, trong đó con trỏ “pre” của “head” trỏ tới “tail” và con trỏ “next” của “tail” trỏ tới “head”.
Các phép toán trên danh sách liên kết
- Tìm kiếm: Tìm kiếm một phần tử đầu tiên có giá trị là “k” trong danh sách liên kết bằng cách duyệt tuần tự và trả về con trỏ trỏ tới phần tử đó.
- Thêm: Để thêm một phần tử vào danh sách liên kết đã có, ta có thể thực hiện theo 3 cách: thêm vào đầu danh sách, thêm vào giữa danh sách hoặc thêm vào cuối danh sách.
- Xoá: Xoá một phần tử “x” khỏi danh sách liên kết. Việc xoá một node có thể thực hiện theo 3 cách: xoá từ đầu danh sách, xoá từ giữa danh sách hoặc xoá từ cuối danh sách.
Ứng dụng của danh sách liên kết
- Được sử dụng trong quản lý bảng ký tự trong thiết kế các trình biên dịch (compiler).
- Được sử dụng trong việc chuyển đổi giữa các ứng dụng bằng phím tắt
Alt + Tab(cài đặt bằng danh sách liên kết vòng).
Ngăn xếp (Stack)
Ngăn xếp là một cấu trúc dữ liệu dạng LIFO (Last In First Out – phần tử được đưa vào sau cùng sẽ được truy cập đầu tiên) thường được sử dụng trong nhiều ngôn ngữ lập trình. Cấu trúc này có tên là “stack” bởi vì nó tương tự như một “stack” trong thực tế – các vật phẩm được xếp chồng lên nhau.
Hoạt động của stack
Có 2 hoạt động cơ bản có thể thực hiện trên một stack, như được mô tả bên dưới:
- Push: Thêm một phần tử vào đỉnh của stack.
- Pop: Xoá một phần tử ở đỉnh của stack. Ngoài ra, có một số hàm khác được bổ sung vào stack để kiểm tra trạng thái của nó, bao gồm:
- Peek: Trả về giá trị của phần tử ở đỉnh của stack mà không xoá nó đi.
- isEmpty: Kiểm tra xem một stack có rỗng hay không.
- isFull: Kiểm tra xem một stack có đầy hay không.
Ứng dụng của stack
- Sử dụng để tính toán giá trị của biểu thức.
- Sử dụng trong lập trình đệ quy để cài đặt lời gọi hàm (function call).
- Các chức năng của hàng đợi (queue) có thể được cài đặt bằng cách sử dụng stack với độ phức tạp là O(log n).
- Sử dụng để tìm giá trị lớn nhất hoặc nhỏ nhất thứ k trong một mảng cho trước.
Hàng đợi (Queue)
Hàng đợi là một cấu trúc dữ liệu dạng FIFO (First In First Out – phần tử được đặt ở đầu sẽ được truy cập đầu tiên) thường được sử dụng trong nhiều ngôn ngữ lập trình. Cấu trúc dữ liệu này được gọi là “queue” bởi nó tương tự như một hàng đợi trong thực tế – một hàng người xếp hàng đợi.
Hoạt động của queue
Có 2 hoạt động cơ bản có thể thực hiện trên một queue, như được mô tả bên dưới:
- Enqueue: Thêm một phần tử vào cuối của queue.
- Dequeue: Xoá phần tử ở đầu của queue.
Ứng dụng của queue
- Sử dụng để quản lý luồng xử lý trong đa luồng (multithreading).
- Sử dụng để cài đặt các hệ thống hàng đợi.
- Hàm của queue có thể được cài đặt bằng cách sử dụng stack với độ phức tạp là O(log n).
- Sử dụng để tìm giá trị lớn nhất hoặc nhỏ nhất thứ k trong một mảng cho trước.
Bảng băm (Hash table)
Bảng băm là một cấu trúc dữ liệu lưu trữ các giá trị, trong đó mỗi giá trị được liên kết với một khóa (key). Bảng băm hỗ trợ tìm kiếm hiệu quả nếu ta biết key của giá trị cần tìm. Do đó, nó rất hiệu quả trong việc thêm, tìm kiếm dữ liệu bất kỳ kích thước nào. Phương pháp đánh địa chỉ trực tiếp sử dụng ánh xạ 1-1 giữa key và value khi lưu trữ trong bảng. Tuy nhiên, cách tiếp cận này có một vấn đề khi có một lượng lớn cặp key-value cần lưu trữ. Kích thước của bảng sẽ trở nên rất lớn và gặp phải vấn đề về lưu trữ. Do đó, để tránh vấn đề này, ta sẽ sử dụng bảng băm.
Hash function
Một hàm đặc biệt được gọi là “hash function (h)” được sử dụng để giải quyết vấn đề của cách tiếp cận đánh địa chỉ trực tiếp. Với cách tiếp cận trực tiếp, một giá trị với key “k” sẽ được lưu trữ trong slot “k”. Sử dụng hàm băm, ta tính toán index của slot mà value được lưu trữ. Giá trị được tính toán bằng hàm băm của một key được gọi là “hash value”, cho biết index của slot mà giá trị sẽ được lưu trữ.
h(k) = k % m- “h”: hàm băm.
- “k”: key của hash value cần xác định.
- “m”: kích thước của bảng băm.
Ứng dụng của bảng băm
- Sử dụng để cài đặt việc đánh index trong cơ sở dữ liệu.
- Sử dụng để cài đặt các danh sách liên kết.
- Sử dụng để cài đặt kiểu cấu trúc dữ liệu “Set”.
Cây (Tree)
Cây là một cấu trúc dữ liệu phân cấp, trong đó các phần tử được tổ chức theo thứ bậc và liên kết với nhau khi lưu trữ. Có nhiều kiểu cây đã được phát triển trong nhiều thập kỷ qua, để phù hợp với các ứng dụng khác nhau hoặc khắc phục những hạn chế cụ thể. Một số ví dụ bao gồm: cây nhị phân (binary tree), cây B (B-tree), treap, cây đỏ-đen (red-black tree), cây quay (splay tree), …
Cây tìm kiếm nhị phân (Binary Search Tree)
Cây tìm kiếm nhị phân là một dạng cây phân cấp, trong đó các phần tử được sắp xếp theo thứ tự tăng dần. Mỗi node trong cây tìm kiếm nhị phân chứa các thuộc tính sau:
- Key: Giá trị được lưu trữ trong node.
- Left: Con trỏ tới con bên trái.
- Right: Con trỏ tới con bên phải.
- P: Con trỏ tới node cha.
- Nếu “y” là node con bên trái của “x”, thì “y.key <= x.key”.
- Nếu “y” là node con bên phải của “x”, thì “y.key >= x.key”.
Ứng dụng của cây
- Cây nhị phân (Binary Trees): Sử dụng để cài đặt phân tích và tính toán biểu thức.
- Cây tìm kiếm nhị phân (Binary Search Tree): Được sử dụng trong nhiều ứng dụng tìm kiếm, nơi dữ liệu được nhập vào và lấy ra theo trật tự.
- Heaps: Được sử dụng trong máy ảo Java (JVM) để lưu trữ đối tượng.
- Treaps: Sử dụng trong mạng không dây.
Heap
Heap là một dạng đặc biệt của cây nhị phân, trong đó node cha so sánh giá trị của mình với các node con để sắp xếp các phần tử cho phù hợp. Hãy xem cách biểu diễn heap dưới đây. Có hai loại heap:
- Min Heap – Giá trị của node cha nhỏ hơn hoặc bằng các node con của nó. Node ở root sẽ có giá trị nhỏ nhất trong heap.
- Max Heap – Giá trị của node cha lớn hơn hoặc bằng các node con của nó. Node ở root sẽ có giá trị lớn nhất trong heap.
Ứng dụng của heap
- Sử dụng trong thuật toán heapsort.
- Sử dụng để triển khai hàng đợi ưu tiên.
- Các chức năng của hàng đợi (queue) có thể được cài đặt bằng cách sử dụng heap với độ phức tạp là O(log n).
- Sử dụng để tìm giá trị lớn nhất hoặc nhỏ nhất thứ k trong một mảng cho trước.
Đồ thị (Graph)
Đồ thị là một tập hợp hữu hạn các đỉnh (nút) và các cạnh kết nối các đỉnh này với nhau. Kích thước của một đồ thị được đo bằng số lượng đỉnh, bậc của đồ thị được đo bằng số lượng cạnh. Hai đỉnh được gọi là kề nhau nếu chúng được nối với nhau bởi một cạnh.
Đồ thị có hướng
Một đồ thị được gọi là đồ thị có hướng nếu mọi đường đi trên đồ thị đều có một chiều giữa điểm đầu và điểm cuối. Ký hiệu “(u, v)” là đường đi từ đỉnh “u” tới đỉnh “v”. “Sefl-loop” là khi một đỉnh có đường đi tới chính nó.
Đồ thị vô hướng
Một đồ thị được gọi là đồ thị vô hướng nếu mọi đường đi trên đồ thị không có chiều. Nếu một đỉnh trong đồ thị không kết nối với bất kỳ đỉnh nào khác, ta nói rằng nó bị cô lập.
Ứng dụng của đồ thị
- Sử dụng để biểu diễn mạng xã hội. Mỗi người dùng là một đỉnh và người dùng sẽ được kết nối với nhau bằng các cạnh.
- Sử dụng để biểu diễn các trang web và liên kết trong các công cụ tìm kiếm. Trang web trên internet sẽ được liên kết tới các trang khác qua các liên kết. Mỗi trang web là một đỉnh và các liên kết sẽ là các cạnh.
- Sử dụng để biểu diễn vị trí và đường đi trong GPS. Vị trí được biểu diễn bởi các đỉnh và đường đi giữa các vị trí là các cạnh. Được sử dụng để tính toán đường đi ngắn nhất giữa 2 địa điểm.
Trên đây là bài viết ngắn gọn của mình nhằm giới thiệu về các cấu trúc dữ liệu thường gặp trong quá trình làm việc. Hy vọng bài viết có thể đem lại kiến thức bổ ích cho bạn.
Phạm Hoài Thương là tác giả chính của website Trường Mầm Non Tuổi Hoa Ba Đình, một người có tâm huyết và đam mê với giáo dục mầm non. Với kinh nghiệm nhiều năm trong lĩnh vực giáo dục và kỹ năng viết lách xuất sắc, cô Thương đã xây dựng nên một trang web hữu ích và thân thiện, mang đến cho phụ huynh những thông tin giá trị về ngôi trường này. Đọc tiếp


